


Site internet sur mesure
Hébergement / Email
DSI Externe
Matériel et logiciels
Notre approche
Nos solutions
Dans un contexte où la disponibilité des services et la réactivité aux incidents sont devenues des enjeux critiques pour les entreprises, la surveillance proactive des systèmes n’est plus une option. C’est une nécessité.
Parmi les outils de supervision open source les plus robustes, Nagios s’est imposé comme une référence incontournable. Voici pourquoi vous devriez envisager sa mise en place sur vos serveurs.
Un serveur peut sembler fonctionnel… jusqu’à ce qu’un service critique tombe sans prévenir. C’est là que Nagios intervient comme outil de détection précoce, en vous permettant de surveiller en continu l’état de vos services, de manière granulaire.
Un bon monitoring ne se limite pas à surveiller. Il doit aussi vous alerter de manière pertinente, ni trop tard, ni pour rien. C’est justement l’une des grandes forces de Nagios : il vous permet de maîtriser totalement votre système d’alertes, pour être réactif sans être submergé.
Avec Nagios, chaque service ou hôte peut être associé à :
Un ou plusieurs contacts
Un ou plusieurs groupes de contacts
Un calendrier de notifications (par exemple, uniquement pendant les heures ouvrées)
Cela permet de configurer précisément qui reçoit quoi, quand, et dans quelles conditions. Par exemple :
Les incidents mineurs remontent uniquement au support de niveau 1
Les alertes critiques en heures non ouvrées vont directement au responsable infrastructure
Les notifications réseau sont séparées des notifications applicatives
Nagios permet de définir des seuils d’alerte différents selon les services :
Température CPU > 60°C = Warning, > 80°C = Critical
Espace disque < 20% = Warning, < 10% = Critical
Temps de réponse HTTP > 1s = Warning, > 3s = Critical
Chaque check peut intégrer ses propres seuils avec une logique conditionnelle, et déclencher des alertes uniquement en cas de dépassement.
Nagios distingue plusieurs états de service :
Et surtout, il permet de :
Ignorer les flaps (états qui oscillent trop souvent)
Mettre des services ou hôtes en maintenance programmée
Définir des règles d’escalade (par exemple : si pas de résolution en 30 minutes, alerter un autre contact ou une autre équipe)
Par défaut, Nagios utilise le mail, mais il peut être étendu facilement pour :
Envoyer des SMS via des passerelles API (Twilio, OVH, etc.)
Créer des tickets automatiquement dans un outil ITSM (GLPI, Jira, Freshdesk…)
Notifier via Slack, Mattermost, Discord, Microsoft Teams, etc.
Déclencher des webhooks pour automatiser des actions (reboot, failover…)
Les plugins communautaires et les scripts personnalisés rendent les possibilités quasiment illimitées.
L’un des grands atouts de Nagios, c’est sa flexibilité. Grâce à son système de plugins, vous pouvez adapter la supervision à n’importe quel environnement, du plus simple au plus complexe.
Nagios repose sur des plugins indépendants, souvent exécutables en ligne de commande.
Résultat : vous pouvez superviser pratiquement tout ce qui est scriptable :
Services système, processus, ressources (via check_*)
Équipements réseaux, imprimantes, onduleurs (via SNMP)
Applications métiers ou SaaS (via API, HTTP, scripts personnalisés)
Besoin spécifique ? Il suffit d’écrire votre propre script en Bash, Python ou autre.

Nagios peut :
Surveiller localement via des plugins classiques
Interroger des hôtes distants via SSH, NRPE ou agents compatibles (NSClient++, SNMP, etc.)
Cela permet de centraliser la supervision de serveurs situés sur différents sites ou dans le cloud, avec une seule interface.
Grâce à son architecture simple, Nagios s’intègre avec :
Des outils de gestion d’incidents (GLPI, OTRS…)
Des plateformes de visualisation (Grafana, Centreon, Thruk…)
Des orchestrateurs d’alertes (Alertmanager, webhook, API)
Surveiller en temps réel, c’est bien. Mais pouvoir analyser a posteriori les incidents, les performances ou les tendances, c’est encore mieux. Nagios vous offre cette capacité grâce à un historique détaillé et des outils de reporting puissants.
Nagios enregistre chaque événement :
Changement d’état (OK → WARNING, etc.)
Heure de détection
Durée de l’incident
Heure de retour à la normale
Notifications envoyées (à qui, quand, pourquoi)
Ces données sont précieuses pour :
Auditer vos temps de réaction
Identifier des causes récurrentes
Répondre à des exigences de traçabilité ou de conformité

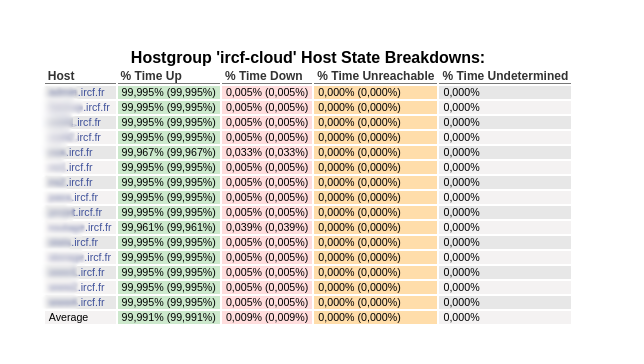
L’interface Nagios propose des vues utiles :
Service Availability Report (taux de disponibilité sur une période donnée)
Host/Service Alert History (liste chronologique des incidents)
Trend Reports (évolution de la charge, de l’usage disque, etc.)
Ces rapports facilitent le pilotage IT, mais servent aussi à objectiver des décisions : augmentation de ressources, remplacement matériel, refonte d’une infra, etc.
Mettre en place Nagios sur votre serveur, c’est reprendre le contrôle de votre infrastructure.
Vous ne subissez plus les pannes, vous les détectez à temps. Vous n’attendez plus les plaintes utilisateurs, vous prévenez les interruptions.
Grâce à son architecture modulaire, ses alertes fines, son historique détaillé et sa maturité, Nagios reste un choix stratégique pour les structures techniques exigeantes.
Que vous soyez une PME souhaitant mieux surveiller ses serveurs internes, ou une entreprise avec des besoins complexes (multi-sites, hébergement hybride, services critiques), nous pouvons vous accompagner à chaque étape :
Audit de votre infrastructure
Déploiement de Nagios ou d’un outil dérivé
Configuration sur mesure (services métiers, seuils personnalisés…)
Développement de plugins spécifiques
Maintenance et supervision externalisée
Notre objectif : vous offrir un monitoring robuste, lisible et vraiment utile.
Contactez-nous pour discuter de vos besoins, ou pour mettre en place un POC (Proof of Concept) rapide sur vos serveurs.